2018年1月31日面试经历
今天面了一家公司,说实话是我面试经历以来最愉快的一次面试经历,在以往的面试中,面试官无非就是问一些老生常谈或者直接从网上搜索的一些面试题,没有深度并且是很少用或者压根就用不着的一些东西,不注重技术问的就像是初中高中考试一样需要死记硬背的东西,在我认为,这些东西固然重要,但是比这些更重要的,是一个人的思想和技术深度,如果去网上背一些面试题就能找到好工作,那程序员的门槛也太低了一些。API是一个工具,而不是需要死记硬背的教科书,我们需要理解它而不是倒背如流。今天面试的这家不一样,比较注重技术深度,在与面试官交流的一个多小时,也使我学到了挺多东西,从心底讲我是非常愿意在这家公司工作的。在面试的过程中,也遇到了一些我不会的东西,所以我就回来之后学习了一些今天面试的内容,大概列出了几条来详细解析一下。
int i = Integer.valueOf(“1”)有什么不好之处?怎么优化
众所周知,Java中有自动拆装箱,从Java1.5开始引入,目的是将原始类型值转自动地转换成对应的对象。自动装箱与拆箱的机制可以让我们在Java的变量赋值或者是方法调用等情况下使用原始类型或者对象类型更加简单直接。这道题目主要是考察的自动拆装箱的知识。
我们首先来看一下valueOf的源码:1
2
3public static Integer valueOf(String s) throws NumberFormatException {
return Integer.valueOf(parseInt(s, 10));
}
可见,在valueOf中是调用了parseInt方法,并且返回的是一个int的包装类型integer的,让我们再看一下parseInt的源码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64public static int parseInt(String s, int radix)
throws NumberFormatException
{
/*
* WARNING: This method may be invoked early during VM initialization
* before IntegerCache is initialized. Care must be taken to not use
* the valueOf method.
*/
if (s == null) {
throw new NumberFormatException("null");
}
if (radix < Character.MIN_RADIX) {
throw new NumberFormatException("radix " + radix +
" less than Character.MIN_RADIX");
}
if (radix > Character.MAX_RADIX) {
throw new NumberFormatException("radix " + radix +
" greater than Character.MAX_RADIX");
}
int result = 0;
boolean negative = false;
int i = 0, len = s.length();
int limit = -Integer.MAX_VALUE;
int multmin;
int digit;
if (len > 0) {
char firstChar = s.charAt(0);
if (firstChar < '0') { // Possible leading "+" or "-"
if (firstChar == '-') {
negative = true;
limit = Integer.MIN_VALUE;
} else if (firstChar != '+')
throw NumberFormatException.forInputString(s);
if (len == 1) // Cannot have lone "+" or "-"
throw NumberFormatException.forInputString(s);
i++;
}
multmin = limit / radix;
while (i < len) {
// Accumulating negatively avoids surprises near MAX_VALUE
digit = Character.digit(s.charAt(i++),radix);
if (digit < 0) {
throw NumberFormatException.forInputString(s);
}
if (result < multmin) {
throw NumberFormatException.forInputString(s);
}
result *= radix;
if (result < limit + digit) {
throw NumberFormatException.forInputString(s);
}
result -= digit;
}
} else {
throw NumberFormatException.forInputString(s);
}
return negative ? result : -result;
}
代码很长,但是我们只看返回值是一个int类型的,所以在valueOf中首先调用了parseInt将String类型转换成了int类型,然后在valueOf中进行了自动装箱,将原始类型int转换成了对应的integer类型,然后在int i = Integer.valueOf(“1”)中,又进行了一次拆箱操作,将integer转换成了int类型,这样做虽然能完成需求,但是自动拆装箱是需要时间的,因此这段代码中是可以优化的,我们可以直接调用parseInt来将String转换成int。省去了一次装箱和一次拆箱的操作,让我们再以代码来看看这两个方法在实际应用中的表现,思路为将int i = Integer.valueOf(“1”)和int i = Integer.parseInt(“1”)循环运行20000000次,然后在循环前调用一下System.currentTimeMillis()获取当前时间,在执行完循环再调用一下System.currentTimeMillis()获取当前时间,然后两个long相减就能获取到执行代码20000000次所需要的时间,但是我在实际操作中,有出现了使用valueOf比parseInt时间少的情况,但是一次两次的情况不等于全部情况,所以我就在main方法中调用了一百次,然后使两个方法所花费的时间相减,看看执行一百次两个方法执行20000000次的结果,代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49/**
* 自动拆装箱效率对比
*
* @date 2018/2/2 11:09:48
* @auther Pyctay
*/
public class Main {
public static void main(String[] args){
int parseIntWin = 0;
int valueOfWin = 0;
int draw = 0;
for(int i = 0;i<100;i++) {
long parseIntSpend = testParseInt();
long valueOfSpend = testValueOf();
if(parseIntSpend-valueOfSpend > 0)
valueOfWin += 1;
else if(parseIntSpend-valueOfSpend < 0)
parseIntWin += 1;
else if(parseIntSpend-valueOfSpend == 0)
draw +=1;
System.out.println();
}
System.out.println("parseInt效率高" + parseIntWin + "次,valueOf效率高" + valueOfWin + "次,平局" + draw + "次");
}
public static long testValueOf(){
long start ;
long end;
start = System.currentTimeMillis();
for(int i=0; i<20000000; i++){
int j = Integer.valueOf("1");
}
end = System.currentTimeMillis();
long total = end - start;
System.out.println("使用valueOf方法总时间为:" + total);
return total;
}
public static long testParseInt(){
long start ;
long end;
start = System.currentTimeMillis();
for(int i=0; i<20000000; i++){
int j = Integer.parseInt("1");
}
end = System.currentTimeMillis();
long total = end - start;
System.out.println("使用parseInt方法总时间为:" + total);
return total;
}
}
执行结果: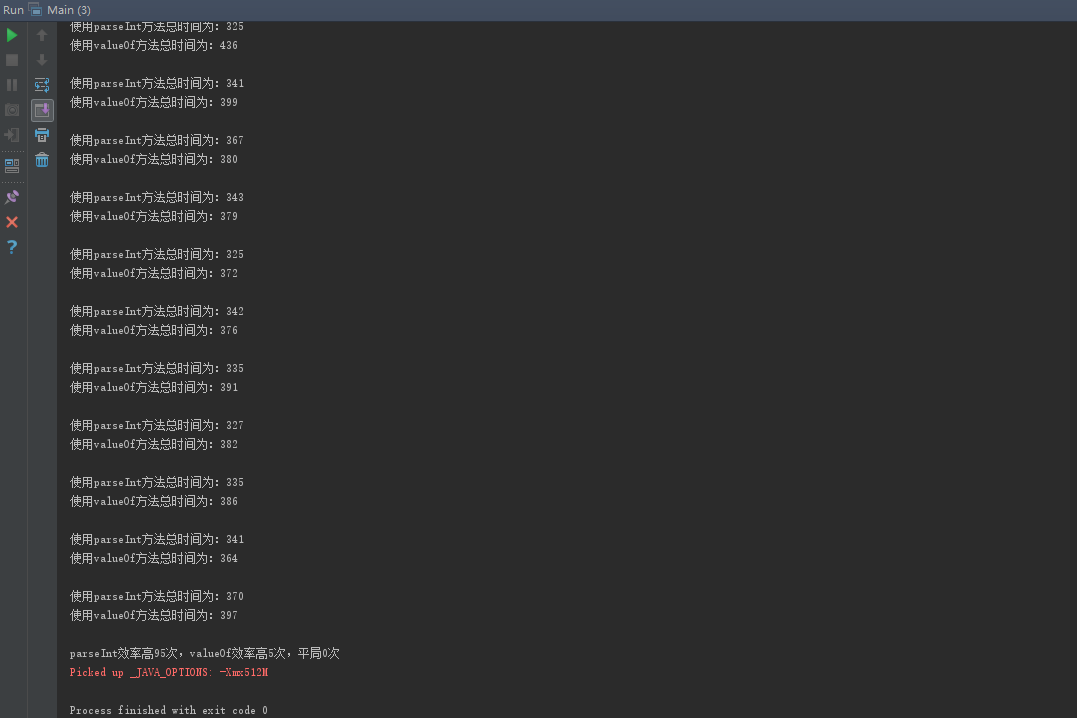
在我多次运行这个测试类时,情况大多维持在95:5左右,由此可见parseInt的效率是高于valueOf的。在此测试类中,我本来是执行10000次的,但是结果很不明显,不能代表实际情况,但是如果数字太大的话执行时间太长。数字越大的话差异就能很好的表现出来,就能很好的代表真实情况。下面是一个运行200000000次的结果: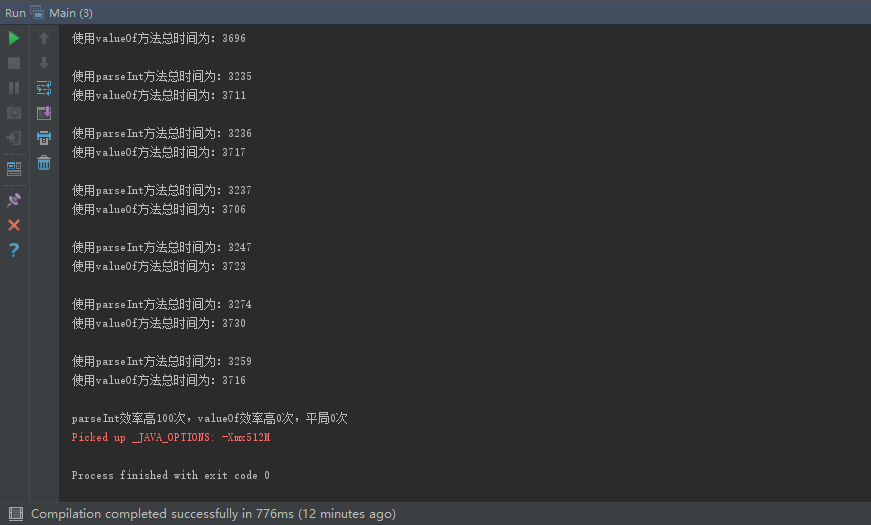
parseInt完胜。
在catch中一般都做什么
在异常体系中,异常处理是非常占用系统资源的,在我认为,能在正常逻辑中做的事情一定不要放在异常中做,在开发阶段,我们在catch中仅仅打印日志,好让我们能够准确的定位异常发生的位置,对代码进行修改,尽量避免异常的发生,但是如果这些异常不是仅仅靠改造代码来避免的呢?(比如停电、断网等)那么我们就需要在代码中尽力处理,对发生的异常进行修正等,以防出现更严重的后果。
Java中垃圾回收流程
Java的垃圾回收分为三个区域新生代 老年代 永久代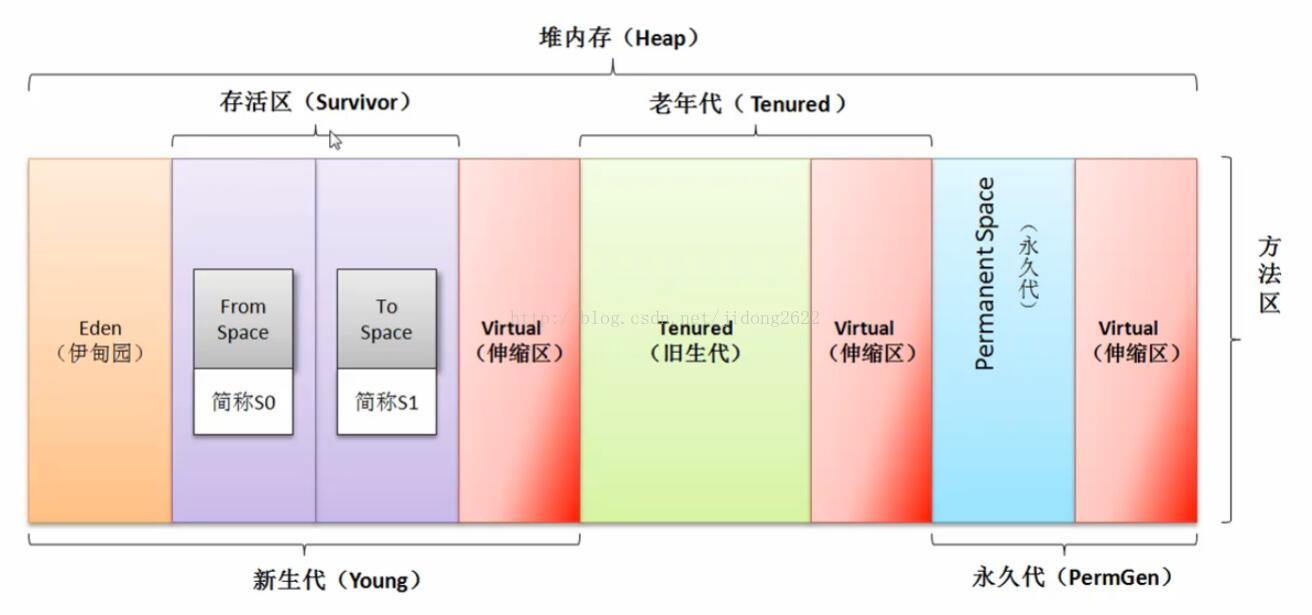
当一个对象创建的时候,首先去Eden区中看看有没有内存,
如果有的话,就直接存储,不进行垃圾回收。
如果Eden区内存已满,会进行一次minor gc
然后再进行判断Eden区中的内存是否足够
如果不足 则去看存活区的内存是否足够.
如果内存足够,把Eden区部分活跃对象保存在存活区,然后把对象保存在Eden区.
如果内存不足,向老年代发送请求,查询老年代的内存是否足够
如果老年代内存足够,将部分存活区的活跃对象存入老年代.然后把Eden区的活跃对象放入存活区,对象依旧保存在Eden区.
如果老年代内存不足,会进行一次full gc,之后老年代会再进行判断 内存是否足够,如果足够 同上.
如果不足 会抛出OutOfMemoryError.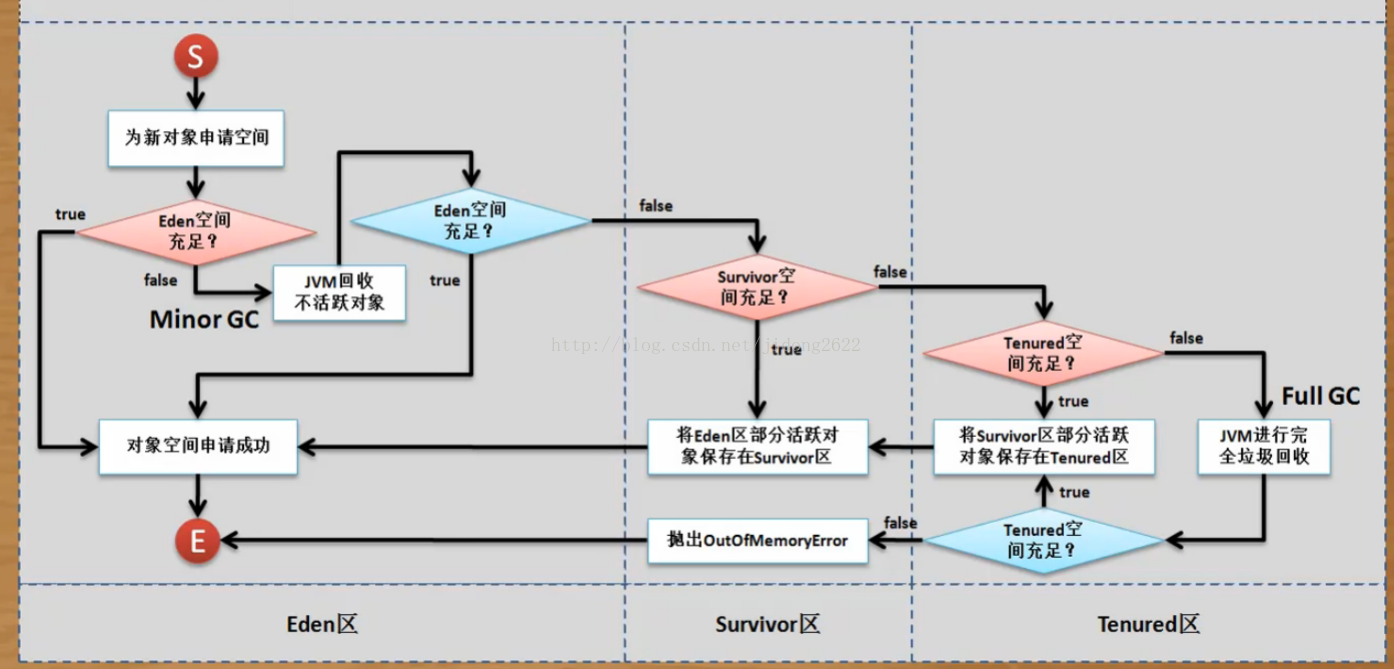
finally中的代码为什么会一定能执行到
在Java中,编译器是通过冗余来实现finally语句块的,即把finally中的字节码”复制”到try块和所有的catch块中。
MySQL的两种引擎
Innodb引擎
支持事务,并且实现SQL标准的四种隔离级别,提供行级锁和外键约束,设计目标是处理大容量数据库系统。但是该引擎不支持FULLTEXT类型的索引,而且它没有保存表的行数,当需要获取表的行数时需要扫描全表,当使用事务时,就需要使用该引擎。
MyIASM引擎
该引擎是MySQL的默认引擎,不支持事务,也不支持行级锁和外键,因此当插入或更新时效率会低一些,不过MyIASM中存储了表的行数,当SELECT COUNT(0) FROM TABLE时只需要直接读取已经保存好的数据而不需要全表扫描,如果表的读操作比较多并且不需要数据库事务时,可以选择该引擎。
数据库索引建立原则
在数据库中,合理的使用索引会提高检索速度,提高系统性能,但是不正确的使用索引不但不能提高性能,并且会拖累系统。下面有几条建立索引的原则:
1.为经常出现在关键字order by、group by、distinct后面的字段,建立索引。
2.在union等集合操作的结果集字段上,建立索引。
3.为经常用作查询选择的字段,建立索引。
4.在经常用作表连接的属性上,建立索引
5.考虑使用索引覆盖。对数据很少被更新的表,如果用户经常只查询其中的几个字段,可以考虑在这几个字段上建立索引,从而将表的扫描改变为索引的扫描。
除了上述几个原则外,我们应该需要注意以下几条:
1.不要过多建立索引,索引虽然提高了访问速度,但是也影响了更新操作的速度,因为更新数据时,索引也需要动态维护。
2.不要在有大量相同取值的字段上,建立索引。(比如性别字段)
3.避免在取值朝一个方向增长的字段(例如:日期类型的字段)上,建立索引;对复合索引,避免将这种类型的字段放置在最前面。
4.对复合索引,按照字段在查询条件中出现的频度建立索引。
5.删除不再使用,或者很少被使用的索引。
Spring的IOC和AOP的核心原理
IOC
IOC是一个容器,根据配置信息,通过Java的反射机制按照配置的依赖关系来生成需要的对象。
AOP
AOP的核心就是代理,在我的设计模式博文中有对代理模式的详细介绍。设计模式之代理设计模式
单例模式实现方式?在什么情况下要必须保证对象的唯一性?工厂模式实现方式?
实现方式在我另外两篇博文中有介绍,在此不再重复介绍。
单例模式:设计模式之单例设计模式
工厂模式:设计模式之工厂模式与抽象工厂模式(浅谈原型模式)
ArrayList、HashMap、LinkedList内部实现方式
ArrayList
通过阅读源码可知,ArrayList内部是维护了一个Object数组,在源码中,有这样三段代码:1
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
1 | /** |
1 |
|
第三段代码是一个无参构造函数,注释的意思大概为ArrayList的容量是这个数组缓冲区的长度,当元素第一次被添加时,将扩大到default_capacity,源码中1
2
3
4 /**
* Default initial capacity.
*/
private static final int DEFAULT_CAPACITY = 10;
这也就是说,不指定ArrayList长度时,ArrayList的初始化长度为10,那么当需要增长的时候是如何操作的呢?下面我们继续看源码:1
2
3
4
5
6
7
8
9
10
11/**
* Appends the specified element to the end of this list.
*
* @param e element to be appended to this list
* @return <tt>true</tt> (as specified by {@link Collection#add})
*/
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
1 | private void ensureCapacityInternal(int minCapacity) { |
1 | /** |
在我们调用add方法时,会调用ensureCapacityInternal方法来判断当前容量是否大于需要的容量,如果不大于则进行扩容操作(grow方法),其中最重要的是int newCapacity = oldCapacity + (oldCapacity >> 1)这行,将旧容量+旧容量右移一位也就是旧容量/2。也就是当容量不够时,ArrayList会自动增长为当前容量的一半。同时,如果当前操作是第一次往ArrayList中添加数据时,minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity),在上面的代码中已经说明DEFAULT_CAPACITY = 10,结果肯定为minCapacity = 10,证实了初始化长度为10。
ArrayList还有一个构造函数:1
2
3
4
5
6
7
8
9
10public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
当创建ArrayList时指定长度的话,会创建一个长度为指定长度的Object数组,如果指定长度为0,那么数组为一个EMPTY_ELEMENTDATA空数组,也就和调用无参构造函数没什么区别了。
LinkedList
LinkedList是通过节点直接彼此连接来实现的。每一个节点都包含前一个节点的引用,后一个节点的引用和节点存储的值。当一个新节点插入时,只需要修改其中保持先后关系的节点的引用即可,当删除记录时也一样。这样就带来以下有缺点:
操作其中对象的速度快 只需要改变连接,新的节点可以在内存中的任何地方
不能随即访问 虽然存在get()方法,但是这个方法是通过遍历接点来定位的所以速度慢。
下面是主要代码:1
2
3
4
5
6
7
8
9
10
11private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
1 | void linkLast(E e) { |
1 | /** |
在调用addLast时,会调用linkLast方法,创建一个静态内部类对象,对象的三个成员分别为:item(内容)、next(下一个内容)、prev(上一个内容),然后更新last为新创建的静态内部类以供下一次使用。LinkedList没有初始大小。
HashMap
HashMap是基于哈希表的Map接口的非同步实现(当时脑子抽了,这么简单的问题没想起来…基于哈希表),HashMap采取数组加链表的存储方式来实现。在源码中,HashMap有三个构造方法:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40/**
* Constructs an empty <tt>HashMap</tt> with the specified initial
* capacity and load factor.
*
* @param initialCapacity the initial capacity
* @param loadFactor the load factor
* @throws IllegalArgumentException if the initial capacity is negative
* or the load factor is nonpositive
*/
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
/**
* Constructs an empty <tt>HashMap</tt> with the specified initial
* capacity and the default load factor (0.75).
*
* @param initialCapacity the initial capacity.
* @throws IllegalArgumentException if the initial capacity is negative.
*/
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
/**
* Constructs an empty <tt>HashMap</tt> with the default initial capacity
* (16) and the default load factor (0.75).
*/
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
还有几个重要的常量:1
2
3static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
static final int MAXIMUM_CAPACITY = 1 << 30;
static final float DEFAULT_LOAD_FACTOR = 0.75f;
由常量可知,hashMap的默认长度为1<<4也就是16,三个构造参数分别是无参构造方法、提供初始长度的构造方法、提供初始长度和负载因子的构造方法,其中第二个构造方法是调用了第一个构造方法并且提供了默认负载因子static final float DEFAULT_LOAD_FACTOR = 0.75f,在第一个构造方法中如果传入的长度大于MAXIMUM_CAPACITY则长度为MAXIMUM_CAPACITY,如果负载因子小于0或者不合法,则抛出IllegalArgumentException异常。
关于扩容的问题,主要是下面这个方法:
1 | /** |
关键代码我已经注释,当需要扩容时,扩容至原来的两倍。
synchronized的内部实现方式?
首先来看JVM规范中描述:
Each object is associated with a monitor. A monitor is locked if and only if it has an owner. The thread that executes monitorenter attempts to gain ownership of the monitor associated with objectref, as follows:
• If the entry count of the monitor associated with objectref is zero, the thread enters the monitor and sets its entry count to one. The thread is then the owner of the monitor.
• If the thread already owns the monitor associated with objectref, it reenters the monitor, incrementing its entry count.
• If another thread already owns the monitor associated with objectref, the thread blocks until the monitor’s entry count is zero, then tries again to gain ownership.
这段话的意思大概为:
每个对象有一个监视器锁(monitor)。当monitor被占用时就会处于锁定状态,线程执行monitorenter指令时尝试获取monitor的所有权,过程如下:
1、如果monitor的进入数为0,则该线程进入monitor,然后将进入数设置为1,该线程即为monitor的所有者。
2、如果线程已经占有该monitor,只是重新进入,则进入monitor的进入数加1.
3.如果其他线程已经占用了monitor,则该线程进入阻塞状态,直到monitor的进入数为0,再重新尝试获取monitor的所有权。
monitorexit:
The thread that executes monitorexit must be the owner of the monitor associated with the instance referenced by objectref.
The thread decrements the entry count of the monitor associated with objectref. If as a result the value of the entry count is zero, the thread exits the monitor and is no longer its owner. Other threads that are blocking to enter the monitor are allowed to attempt to do so.
这段话的大概意思为:
执行monitorexit的线程必须是objectref所对应的monitor的所有者。
指令执行时,monitor的进入数减1,如果减1后进入数为0,那线程退出monitor,不再是这个monitor的所有者。其他被这个monitor阻塞的线程可以尝试去获取这个 monitor 的所有权。
通过上述两段的描述,我们就能大概了解synchronized的内部实现原理,Synchronized的语义底层是通过一个monitor的对象来完成,其实wait/notify等方法也依赖于monitor对象,这就是为什么只有在同步的块或者方法中才能调用wait/notify等方法,否则会抛出java.lang.IllegalMonitorStateException的异常的原因。
当Synchronized修饰方法时,当方法调用时,调用指令将会检查方法的 ACC_SYNCHRONIZED 访问标志是否被设置,如果设置了,执行线程将先获取monitor,获取成功之后才能执行方法体,方法执行完后再释放monitor。在方法执行期间,其他任何线程都无法再获得同一个monitor对象。 其实本质上没有区别,只是方法的同步是一种隐式的方式来实现,无需通过字节码来完成。
怎么保证访问到一个变量时都是这个变量的最新状态?
Java语言提供了一种稍弱的同步机制,即volatile变量,用来确保将变量的更新操作通知到其他线程。当把变量声明为volatile类型后,编译器与运行时都会注意到这个变量是共享的,因此不会将该变量上的操作与其他内存操作一起重排序。volatile变量不会被缓存在寄存器或者对其他处理器不可见的地方,因此在读取volatile类型的变量时总会返回最新写入的值。
当且仅当满足以下所有条件时,才应该使用volatile变量
1.对变量的写入操作不依赖变量的当前值,或者你能确保只有单个线程更新变量的。值例如:count++、。
2.该变量没有包含在具有其他变量的不变式中。
在两个或者更多的线程需要访问的成员变量上使用volatile。当要访问的变量已在synchronized代码块中,或者为常量时,没必要使用volatile。
equals为true,hashCode也相等么?反之,hashCode相等那么equals也一定相等么?
答案是两个对象equals为true时,hashCode一定相等,但是hashCode相等时,两个对象equals不一定为true。
关于这个问题我有一篇博文详细介绍了覆盖equals需要注意的事项
二维码: